
Google in the present day launched its seventh-generation Tensor Processing Unit, “Ironwood,” which the corporate stated is it most performant and scalable customized AI accelerator and the primary designed particularly for inference.
Ironwood scales as much as 9,216 liquid cooled chips linked by way of Inter-Chip Interconnect (ICI) networking spanning almost 10 MW. It’s a new parts of Google Cloud AI Hypercomputer structure, constructed to optimize {hardware} and software program collectively for AI workloads, in keeping with the corporate. Ironwood lets builders leverage Google’s Pathways software program stack to harness tens of hundreds of Ironwood TPUs.
Ironwood represents a shift from responsive AI fashions, which give real-time info for individuals to interpret, to fashions that present the proactive era of insights and interpretation, in keeping with Google.
“That is what we name the “age of inference” the place AI brokers will proactively retrieve and generate information to collaboratively ship insights and solutions, not simply information,” they stated.
Ironwood is designed to handle the omputation and communication calls for of “pondering fashions,” encompassing massive language fashions, Combination of Specialists (MoEs) and superior reasoning duties, which require large parallel processing and environment friendly reminiscence entry. Google stated Ironwood is designed to reduce information motion and latency on chip whereas finishing up large tensor manipulations.
“On the frontier, the computation calls for of pondering fashions lengthen properly past the capability of any single chip,” they stated. “We designed Ironwood TPUs with a low-latency, excessive bandwidth ICI community to help coordinated, synchronous communication at full TPU pod scale.”
Ironwood is available in two sizes primarily based on AI workload calls for: a 256 chip configuration and a 9,216 chip configuration.
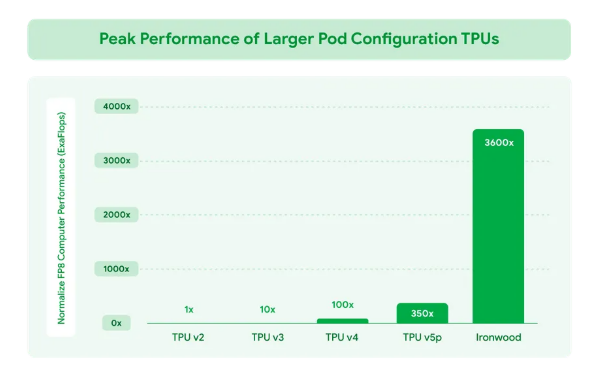
- When scaled to 9,216 chips per pod for a complete of 42.5 exaflops, Ironwood helps greater than 24x the compute energy of the world’s no. 1 supercomputer on the Top500 record – El Capitan, at 1.7 exaflops per pod, Google stated. Every Ironwood chip has peak compute of 4,614 TFLOPs. “This represents a monumental leap in AI functionality. Ironwood’s reminiscence and community structure ensures that the proper information is all the time out there to help peak efficiency at this large scale,” they stated.
- Ironwood additionally options SparseCore, a specialised accelerator for processing ultra-large embeddings frequent in superior rating and suggestion workloads. Expanded SparseCore help in Ironwood permits for a wider vary of workloads to be accelerated, together with transferring past the standard AI area to monetary and scientific domains.
- Pathways, Google’s ML runtime developed by Google DeepMind, allows distributed computing throughout a number of TPU chips. Pathways on Google is designed to make transferring past a single Ironwood Pod simple, enabling a whole lot of hundreds of Ironwood chips to be composed collectively for AI computation.
 Options embrace:
Options embrace:
- Ironwood perf/watt is 2x relative to Trillium, our sixth era TPU announced last year. At a time when out there energy is likely one of the constraints for delivering AI capabilities, we ship considerably extra capability per watt for buyer workloads. Our superior liquid cooling options and optimized chip design can reliably maintain as much as twice the efficiency of ordinary air cooling even underneath steady, heavy AI workloads. In reality, Ironwood is almost 30x extra energy environment friendly than the corporate’s first cloud TPU from 2018.
- Ironwood affords 192 GB per chip, 6x that of Trillium, designed to allow processing of bigger fashions and datasets, decreasing information transfers and enhancing efficiency.
- Improved HBM bandwidth, reaching 7.2 TBps per chip, 4.5x of Trillium’s. This ensures fast information entry, essential for memory-intensive workloads frequent in trendy AI.
- Enhanced Inter-Chip Interconnect (ICI) bandwidth has been elevated to 1.2 Tbps bidirectional, 1.5x of Trillium’s, enabling quicker communication between chips, facilitating environment friendly distributed coaching and inference at scale.