
In July 1959, Arthur Samuel developed one of many first brokers to play the sport of checkers. What constitutes an agent that performs checkers could be finest described in Samuel’s personal phrases, “…a pc [that] could be programmed so that it’ll be taught to play a greater recreation of checkers than could be performed by the one who wrote this system” [1]. The checkers’ agent tries to comply with the concept of simulating each potential transfer given the present scenario and choosing essentially the most advantageous one i.e. one which brings the participant nearer to profitable. The transfer’s “advantageousness” is set by an analysis operate, which the agent improves by means of expertise. Naturally, the idea of an agent just isn’t restricted to the sport of checkers, and plenty of practitioners have sought to match or surpass human efficiency in in style video games. Notable examples embrace IBM’s Deep Blue (which managed to defeat Garry Kasparov, a chess world champion on the time), and Tesauro’s TD-Gammon, a temporal-difference strategy, the place the analysis operate was modelled utilizing a neural community. In actual fact, TD-Gammon’s taking part in type was so unusual that some consultants even adopted some methods it conjured up [2].
Unsurprisingly, analysis into creating such ‘brokers’ solely skyrocketed, with novel approaches in a position to attain peak human efficiency in advanced video games. On this put up, we discover one such strategy: the DQN strategy launched in 2013 by Mnih et al, through which taking part in Atari video games is approached by means of a synthesis of Deep Neural Networks and TD-Studying (NB: the unique paper got here out in 2013, however we are going to deal with the 2015 model which comes with some technical enhancements) [3, 4]. Earlier than we proceed, you must word that within the ever-expanding house of recent approaches, DQN has been outmoded by sooner and extra refined state-of-the-art strategies. But, it stays an excellent stepping stone within the subject of Deep Reinforcement Studying, well known for combining deep studying with reinforcement studying. Therefore, readers aiming to dive into Deep-RL are inspired to start with DQN.
This put up is sectioned as follows: first, I outline the issue with taking part in Atari video games and clarify why some conventional strategies could be intractable. Lastly, I current the specifics of the DQN strategy and dive into the technical implementation.
The Drawback At Hand
For the rest of the put up, I’ll assume that you understand the fundamentals of supervised studying, neural networks (fundamental FFNs and CNNs) and in addition fundamental reinforcement studying ideas (Bellman equations, TD-learning, Q-learning and so on) If a few of these RL ideas are overseas to you, then this playlist is an efficient introduction.
Atari is a nostalgia-laden time period, that includes iconic video games equivalent to Pong, Breakout, Asteroids and plenty of extra. On this put up, we limit ourselves to Pong. Pong is a 2-player recreation, the place every participant controls a paddle and might use mentioned paddle to hit the incoming ball. Factors are scored when the opponent is unable to return the ball, in different phrases, the ball goes previous them. A participant wins after they attain 21 factors.
Contemplating the sequential nature of the sport, it is likely to be acceptable to border the issue as an RL downside, after which apply one of many resolution strategies. We are able to body the sport as an MDP:

The states would characterize the present recreation state (the place the ball or participant paddle is and so on, analogous to the concept of a search state). The rewards encapsulate our concept of profitable and the actions correspond to the buttons on the Atari 2600 console. Our aim now turns into discovering a coverage

often known as the optimum coverage. Let’s see what would possibly occur if we attempt to practice an agent utilizing some classical RL algorithms.
An easy resolution would possibly entail fixing the issue utilizing a tabular strategy. We may enumerate all states (and actions) and affiliate every state with a corresponding state or state-action worth. We may then apply one of many classical RL strategies (Monte-Carlo, TD-Studying, Worth Iteration and so on), taking a dynamic Programming strategy. Nevertheless, using this strategy faces massive pitfalls quite shortly. What can we think about as states? What number of states do we now have to enumerate?
It shortly turns into fairly tough to reply these questions. Defining a state turns into tough as many parts are in play when contemplating the concept of a state (i.e. the states have to be Markovian, encapsulate a search state and so on). What about visible output (frames) to characterize a state? In spite of everything that is how we as people work together with Atari video games. We see frames, deduce data relating to the sport state after which select the suitable motion. Nevertheless, there are impossibly many states when utilizing this illustration, which might make our tabular strategy fairly intractable, memory-wise.
Now for the sake of argument think about that we now have sufficient reminiscence to carry a desk of this dimension. Even then we would wish to discover all of the states a superb variety of instances to get good approximations of the worth operate. We would wish to discover all potential states (or state-action) sufficient instances to reach at a helpful worth. Herein lies the runtime hurdle; it will be fairly infeasible for the values to converge for all of the states within the desk in an affordable period of time as we now have infinite states.
Maybe as a substitute of framing it as a reinforcement studying downside, can we as a substitute rephrase it right into a supervised studying downside? Maybe a formulation through which the states are samples and the labels are the actions carried out. Even this attitude brings forth new issues. Atari video games are inherently sequential, every state is sampled based mostly on the earlier. This breaks the i.i.d assumptions utilized in supervised studying, negatively affecting supervised learning-based options. Equally, we would wish to create a hand-labelled dataset, maybe using a human skilled at hand label actions for every body. This is able to be costly and laborious, and nonetheless would possibly yield inadequate outcomes.
Solely counting on both supervised studying or RL could result in inefficient studying, whether or not as a consequence of computational constraints or suboptimal insurance policies. This requires a extra environment friendly strategy to fixing Atari video games.
DQN: Instinct & Implementation
I assume you may have some fundamental information of PyTorch, Numpy and Python, although I’ll attempt to be as articulate as potential. For these unfamiliar, I like to recommend consulting: pytorch & numpy.
Deep-Q Networks purpose to beat the aforementioned limitations by means of a wide range of strategies. Let’s undergo every of the issues step-by-step and handle how DQN mitigates or solves these challenges.
It’s fairly laborious to give you a proper state definition for Atari video games as a consequence of their range. DQN is designed to work for many Atari video games, and consequently, we’d like a acknowledged formalization that’s appropriate with mentioned video games. To this finish, the visible illustration (pixel values) of the video games at any given second are used to vogue a state. Naturally, this entails a steady state house. This connects to our earlier dialogue on potential methods to characterize states.
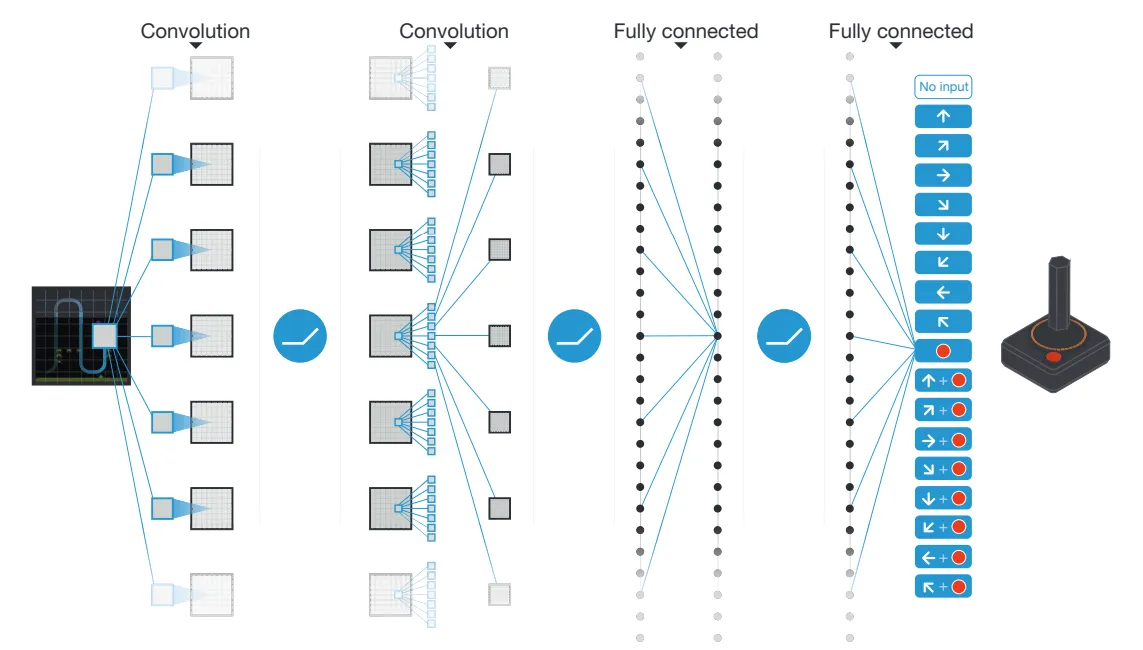
The problem of steady states is solved by means of operate approximation. Perform approximation (FA) goals to approximate the state-action worth operate instantly utilizing a operate approximation. Let’s undergo the steps to know what the FA does.
Think about that we now have a community that given a state outputs the worth of being in mentioned state and performing a sure motion. We then choose actions based mostly on the best reward. Nevertheless, this community can be short-sighted, solely considering one timestep. Can we incorporate potential rewards from additional down the road? Sure we are able to! That is the concept of the anticipated return. From this view, the FA turns into fairly easy to know; we purpose to discover a operate:

In other words, a function which outputs the expected return of being in a given state after performing an action.
This idea of approximation becomes crucial due to the continuous nature of the state space. By using a FA, we can exploit the idea of generalization. States close to each other (similar pixel values) will have similar Q-values, meaning that we don’t need to cover the entire (infinite) state space, greatly lowering our computational overhead.
DQN employs FA in tandem with Q-learning. As a small refresher, Q-learning aims to find the expected return for being in a state and performing a certain action using bootstrapping. Bootstrapping models the expected return that we mentioned using the current Q-function. This ensures that we don’t need to wait till the end of an episode to update our Q-function. Q-learning is also 0ff-policy, which means that the data we use to learn the Q-function is different from the actual policy being learned. The resulting Q-function then corresponds to the optimal Q-function and can be used to find the optimal policy (just find the action that maximizes the Q-value in a given state). Moreover, Q-learning is a model-free solution, meaning that we don’t need to know the dynamics of the environment (transition functions etc) to learn an optimal policy, unlike in value iteration. Thus, DQN is also off-policy and model-free.
By using a neural network as our approximator, we need not construct a full table containing all the states and their respective Q-values. Our neural network will output the Q-value for being a given state and performing a certain action. From this point on, we refer to the approximator as the Q-network.
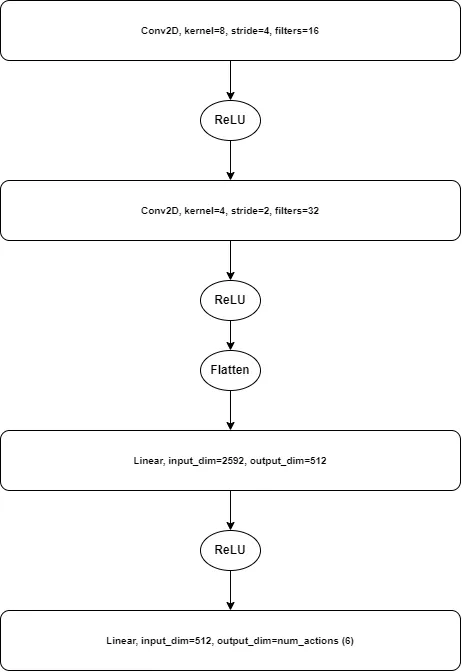
Since our states are defined by images, using a basic feed-forward network (FFN) would incur a large computational overhead. For this specific reason, we employ the use of a convolutional network, which is much better able to learn the distinct features of each state. The CNNs are able to distill the images down to a representation (this is the idea of representation learning), which is then fed to a FFN. The neural network architecture can be seen above. Instead of returning one value for:

we return an array with each value corresponding to a possible action in the given state (for Pong we can perform 6 actions, so we return 6 values).
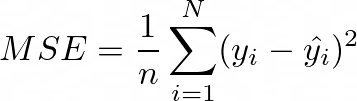
Recall that to train a neural network we need to define a loss function that captures our goals. DQN uses the MSE loss function. For the predicted values we the output of our Q-network. For the true values, we use the bootstrapped values. Hence, our loss function becomes the following:

If we differentiate the loss function with respect to the weights we arrive at the following equation.
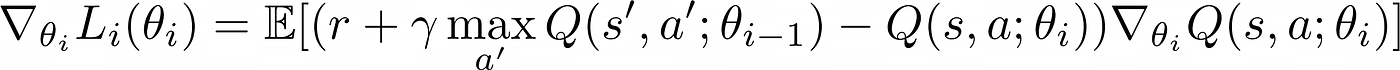
Plugging this into the stochastic gradient descent (SGD) equation, we arrive at Q-learning [4].
By performing SGD updates using the MSE loss function, we perform Q-learning. However, this is an approximation of Q-learning, as we don’t update on a single move but instead on a batch of moves. The expectation is simplified for expedience, though the message remains the same.
From another perspective, you can also think of the MSE loss function as nudging the predicted Q-values as close to the bootstrapped Q-values (after all this is what the MSE loss intends). This inadvertently mimics Q-learning, and slowly converges to the optimal Q-function.
By employing a function approximator, we become subject to the conditions of supervised learning, namely that the data is i.i.d. But in the case of Atari games (or MDPs) this condition is often not upheld. Samples from the environment are sequential in nature, making them dependent on each other. Similarly, as the agent improves the value function and updates its policy, the distribution from which we sample also changes, violating the condition of sampling from an identical distribution.
To solve this the authors of DQN capitalize on the idea of an experience replay. This concept is core to keep the training of DQN stable and convergent. An experience replay is a buffer which stores the tuple (s, a, r, s’, d) where s, a, r, s’ are returned after performing an action in an MDP, and d is a boolean representing whether the episode has finished or not. The replay has a maximum capacity which is defined beforehand. It might be simpler to think of the replay as a queue or a FIFO data structure; old samples are removed to make room for new samples. The experience replay is used to sample a random batch of tuples which are then used for training.
The experience replay helps with the alleviation of two major challenges when using neural network function approximators with RL problems. The first deals with the independence of the samples. By randomly sampling a batch of moves and then using those for training we decouple the training process from the sequential nature of Atari games. Each batch may have actions from different timesteps (or even different episodes), giving a stronger semblance of independence.
Secondly, the experience replay addresses the issue of non-stationarity. As the agent learns, changes in its behaviour are reflected in the data. This is the idea of non-stationarity; the distribution of data changes over time. By reusing samples in the replay and using a FIFO structure, we limit the adverse effects of non-stationarity on training. The distribution of the data still changes, but slowly and its effects are less impactful. Since Q-learning is an off-policy algorithm, we still end up learning the optimal policy, making this a viable solution. These changes allow for a more stable training procedure.
As a serendipitous side effect, the experience replay also allows for better data efficiency. Before training examples were discarded after being used for a single update step. However, through the use of an experience replay, we can reuse moves that we have made in the past for updates.
A change made in the 2015 Nature version of DQN was the introduction of a target network. Neural networks are fickle; slight changes in the weights can introduce drastic changes in the output. This is unfavourable for us, as we use the outputs of the Q-network to bootstrap our targets. If the targets are prone to large changes, it will destabilize training, which naturally we want to avoid. To alleviate this issue, the authors introduce a target network, which copies the weights of the Q-network every set amount of timesteps. By using the target network for bootstrapping, our bootstrapped targets are less unstable, making training more efficient.
Lastly, the DQN authors stack four consecutive frames after executing an action. This remark is made to ensure the Markovian property holds [9]. A singular frame omits many details of the game state such as the velocity and direction of the ball. A stacked representation is able to overcome these obstacles, providing a holistic view of the game at any given timestep.
With this, we have covered most of the major techniques used for training a DQN agent. Let’s go over the training procedure. The procedure will be more of an overview, and we’ll iron out the details in the implementation section.
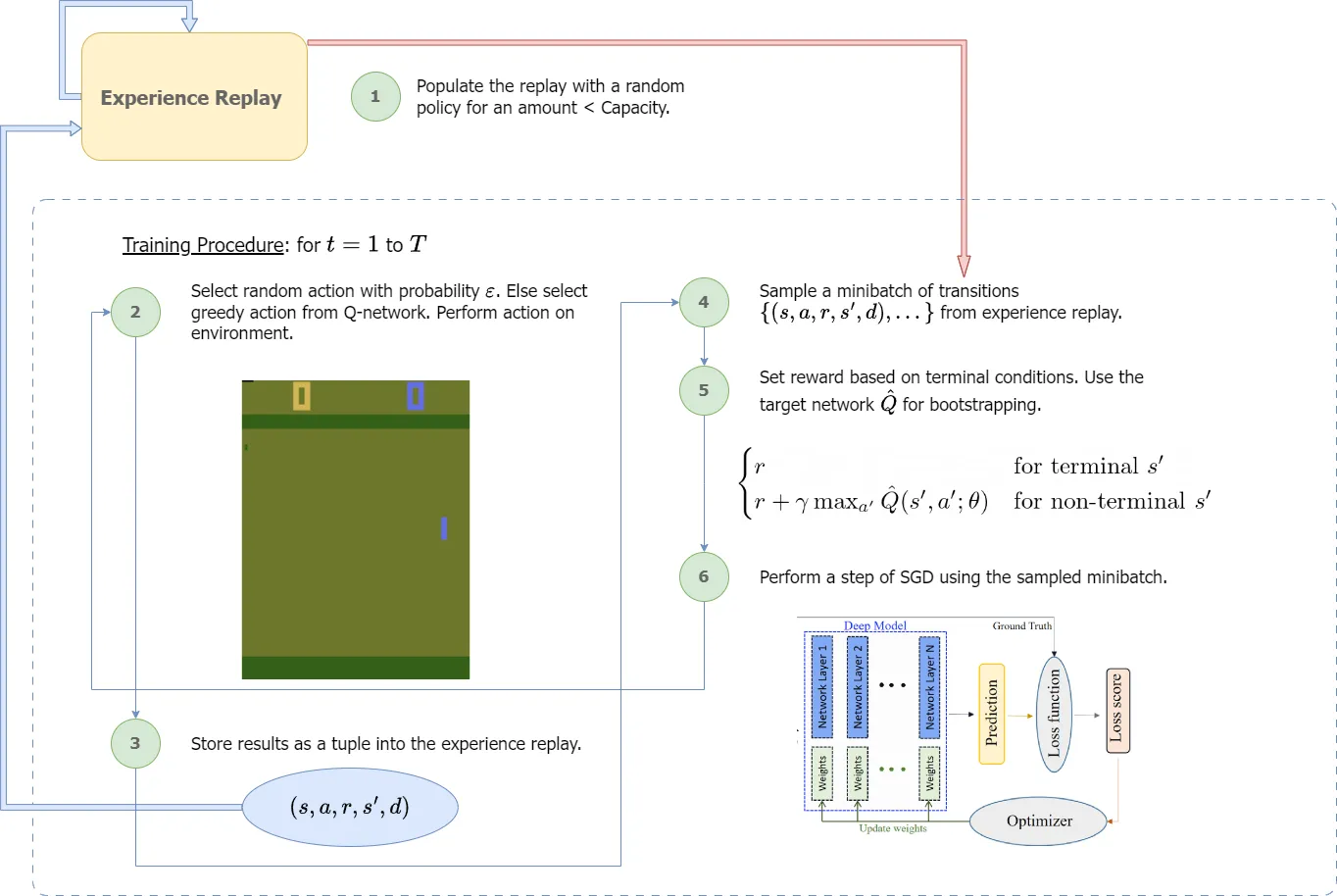
One important clarification arises from step 2. In this step, we perform a process called ε-greedy action selection. In ε-greedy, we randomly choose an action with probability ε, and otherwise choose the best possible action (according to our learned Q-network). Choosing an appropriate ε allows for the sufficient exploration of actions which is crucial to converge to a reliable Q-function. We often start with a high ε and slowly decay this value over time.
Implementation
If you want to follow along with my implementation of DQN then you will need the following libraries (apart from Numpy and PyTorch). I provide a concise explanation of their use.
- Arcade Learning Environment → ALE is a framework that permits us to work together with Atari 2600 environments. Technically we interface ALE by means of gymnasium, an API for RL environments and benchmarking.
- StableBaselines3 → SB3 is a deep reinforcement studying framework with a backend designed in Pytorch. We are going to solely want this for some preprocessing wrappers.
Let’s import the entire essential libraries.
import numpy as np
import time
import torch
import torch.nn as nn
import gymnasium as fitness center
import ale_py
from collections import deque # FIFO queue knowledge structurefrom tqdm import tqdm # progress barsfrom gymnasium.wrappers import FrameStack
from gymnasium.wrappers.frame_stack import LazyFrames
from stable_baselines3.widespread.atari_wrappers import (
AtariWrapper,
FireResetEnv,
)
fitness center.register_envs(ale_py) # we have to register ALE with fitness center
# use cuda you probably have it in any other case cpu
system="cuda" if torch.cuda.is_available() else 'cpu'
systemFirst, we assemble an atmosphere, utilizing the ALE framework. Since we’re working with pong we create an atmosphere with the title PongNoFrameskip-v4. With this, we are able to create an atmosphere utilizing the next code:
env = fitness center.make('PongNoFrameskip-v4', render_mode="rgb_array")The rgb_array parameter tells ALE to return pixel values as a substitute of RAM codes (which is the default). The code to work together with the Atari turns into very simple with fitness center. The next excerpt encapsulates many of the utilities that we’ll want from fitness center.
# this code restarts/begins a atmosphere to the start of an episode
remark, _ = env.reset()
for _ in vary(100): # variety of timesteps
# randomly get an motion from potential actions
motion = env.action_space.pattern()
# take a step utilizing the given motion
# observation_prime refers to s', terminated and truncated seek advice from
# whether or not an episode has completed or been minimize brief
observation_prime, reward, terminated, truncated, _ = env.step(motion)
remark = observation_primeWith this, we’re given states (we title them observations) with the form (210, 160, 3). Therefore the states are RGB pictures with the form 210×160. An instance could be seen in Determine 2. When coaching our DQN agent, a picture of this dimension provides pointless computational overhead. The same remark could be made about the truth that the frames are RGB (3 channels).
To unravel this, we downsample the body all the way down to 84×84 and rework it into grayscale. We are able to do that by using a wrapper from SB3, which does this for us. Now each time we carry out an motion our output shall be in grayscale (with 1 channel) and of dimension 84×84.
env = AtariWrapper(env, terminal_on_life_loss=False, frame_skip=4)The wrapper above does greater than downsample and switch our body into grayscale. Let’s go over another adjustments the wrapper introduces.
- Noop Reset → The beginning state of every Atari recreation is deterministic, i.e. you begin on the identical state every time the sport ends. With this the agent could be taught to memorize a sequence of actions from the beginning state, leading to a sub-optimal coverage. To forestall this, we carry out no actions for a set quantity of timesteps to start with.
- Body Skipping → Within the ALE atmosphere every body wants an motion. As an alternative of selecting an motion at every body, we choose an motion and repeat it for a set variety of timesteps. That is the concept of body skipping and permits for smoother transitions.
- Max-pooling → As a result of method through which ALE/Atari renders its frames and the downsampling, it’s potential that we encounter flickering. To unravel this we take the max over two consecutive frames.
- Terminal Life on Loss → Many Atari video games don’t finish when the participant dies. Think about Pong, no participant wins till the rating hits 21. Nevertheless, by default brokers would possibly think about the lack of life as the top of an episode, which is undesirable. This wrapper counteracts this and ends the episode when the sport is actually over.
- Clip Reward → The gradients are extremely delicate to the magnitude of the rewards. To keep away from unstable updates, we clip the rewards to be between {-1, 0, 1}.
Aside from these we additionally introduce an extra body stack wrapper (FrameStack). This performs what was mentioned above, stacking 4 frames on prime of every to maintain the states Markovian. The ALE atmosphere returns LazyFrames, that are designed to be extra reminiscence environment friendly, as the identical body would possibly happen a number of instances. Nevertheless, they don’t seem to be appropriate with lots of the operations that we carry out all through the coaching process. To transform LazyFrames into usable objects, we apply a customized wrapper which converts an remark to Numpy earlier than returning it to us. The code is proven beneath.
class LazyFramesToNumpyWrapper(fitness center.ObservationWrapper): # subclass obswrapper
def __init__(self, env):
tremendous().__init__(env)
self.env = env # the atmosphere that we need to convert
def remark(self, remark):
# if its a LazyFrames object then flip it right into a numpy array
if isinstance(remark, LazyFrames):
return np.array(remark)
return remarkLet’s mix the entire wrappers into one operate that returns an atmosphere that does the entire above.
def make_env(recreation, render="rgb_array"):
env = fitness center.make(recreation, render_mode=render)
env = AtariWrapper(env, terminal_on_life_loss=False, frame_skip=4)
env = FrameStack(env, num_stack=4)
env = LazyFramesToNumpyWrapper(env)
# generally a atmosphere wants that the hearth button be
# pressed to start out the sport, this makes positive that recreation is began when wanted
if "FIRE" in env.unwrapped.get_action_meanings():
env = FireResetEnv(env)
return envThese adjustments are derived from the 2015 Nature paper and assist to stabilize coaching [3]. The interfacing with fitness center stays the identical as proven above. An instance of the preprocessed states could be seen in Determine 7.
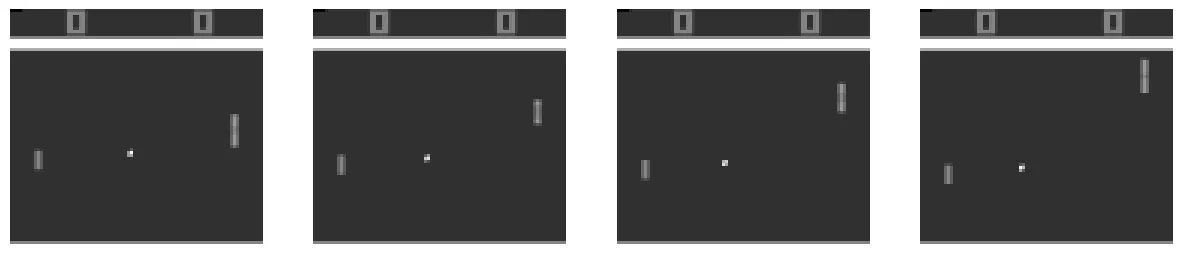
Now that we now have an acceptable atmosphere let’s transfer on to create the replay buffer.
class ReplayBuffer:
def __init__(self, capability, system):
self.capability = capability
self._buffer = np.zeros((capability,), dtype=object) # shops the tuples
self._position = 0 # maintain monitor of the place we're
self._size = 0
self.system = system
def retailer(self, expertise):
"""Provides a brand new expertise to the buffer,
overwriting previous entries when full."""
idx = self._position % self.capability # get the index to switch
self._buffer[idx] = expertise
self._position += 1
self._size = min(self._size + 1, self.capability) # max dimension is the capability
def pattern(self, batch_size):
""" Pattern a batch of tuples and cargo it onto the system
"""
# if the buffer just isn't full capability then return all the pieces we now have
buffer = self._buffer[0:min(self._position-1, self.capacity-1)]
# minibatch of tuples
batch = np.random.alternative(buffer, dimension=[batch_size], substitute=True)
# we have to return the objects as torch tensors, therefore we delegate
# this job to the rework operate
return (
self.rework(batch, 0, form=(batch_size, 4, 84, 84), dtype=torch.float32),
self.rework(batch, 1, form=(batch_size, 1), dtype=torch.int64),
self.rework(batch, 2, form=(batch_size, 1), dtype=torch.float32),
self.rework(batch, 3, form=(batch_size, 4, 84, 84), dtype=torch.float32),
self.rework(batch, 4, form=(batch_size, 1), dtype=torch.bool)
)
def rework(self, batch, index, form, dtype):
""" Rework a handed batch right into a torch tensor for a given axis.
E.g. if index 0 of a tuple means the state then we return all states
as a torch tensor. We additionally return a specified form.
"""
# reshape the tensors as wanted
batched_values = np.array([val[index] for val in batch]).reshape(form)
# convert to torch tensors
batched_values = torch.as_tensor(batched_values, dtype=dtype, system=self.system)
return batched_values
# beneath are some magic strategies I used for debugging, not crucial
# they only flip the item into an arraylike object
def __len__(self):
return self._size
def __getitem__(self, index):
return self._buffer[index]
def __setitem__(self, index, worth: tuple):
self._buffer[index] = worthThe replay buffer works by allocating house within the reminiscence for the given capability. We keep a pointer that retains monitor of the variety of objects added. Each time a brand new tuple is added we substitute the oldest tuples with the brand new ones. To pattern a minibatch, we first randomly pattern a minibatch in numpy after which convert it into torch tensors, additionally loading it to the suitable system.
A few of the points of the replay buffer are impressed by [8]. The replay buffer proved to be the most important bottleneck in coaching the agent, and thus small speed-ups within the code proved to be monumentally essential. Another technique which makes use of an deque object to carry the tuples may also be used. In case you are creating your individual buffer, I might emphasize that you just spend slightly extra time to make sure its effectivity.
We are able to now use this to create a operate that creates a buffer and preloads a given variety of tuples with a random coverage.
def load_buffer(preload, capability, recreation, *, system):
# make the atmosphere
env = make_env(recreation)
# create the buffer
buffer = ReplayBuffer(capability,system=system)
# begin the atmosphere
remark, _ = env.reset()
# run for so long as the required preload
for _ in tqdm(vary(preload)):
# pattern random motion -> random coverage
motion = env.action_space.pattern()
observation_prime, reward, terminated, truncated, _ = env.step(motion)
# retailer the outcomes from the motion as a python tuple object
buffer.retailer((
remark.squeeze(), # squeeze will take away the pointless grayscale channel
motion,
reward,
observation_prime.squeeze(),
terminated or truncated))
# set previous remark to be new observation_prime
remark = observation_prime
# if the episode is finished, then restart the atmosphere
achieved = terminated or truncated
if achieved:
remark, _ = env.reset()
# return the env AND the loaded buffer
return buffer, envThe operate is sort of easy, we create a buffer and atmosphere object after which preload the buffer utilizing a random coverage. Word that we squeeze the observations to take away the redundant coloration channel. Let’s transfer on to the subsequent step and outline the operate approximator.
class DQN(nn.Module):
def __init__(
self,
env,
in_channels = 4, # variety of stacked frames
hidden_filters = [16, 32],
start_epsilon = 0.99, # beginning epsilon for epsilon-decay
max_decay = 0.1, # finish epsilon-decay
decay_steps = 1000, # how lengthy to succeed in max_decay
*args,
**kwargs
) -> None:
tremendous().__init__(*args, **kwargs)
# instantiate occasion vars
self.start_epsilon = start_epsilon
self.epsilon = start_epsilon
self.max_decay = max_decay
self.decay_steps = decay_steps
self.env = env
self.num_actions = env.action_space.n
# Sequential is an arraylike object that permits us to
# carry out the ahead go in a single line
self.layers = nn.Sequential(
nn.Conv2d(in_channels, hidden_filters[0], kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(hidden_filters[0], hidden_filters[1], kernel_size=4, stride=2),
nn.ReLU(),
nn.Flatten(start_dim=1),
nn.Linear(hidden_filters[1] * 9 * 9, 512), # the ultimate worth is calculated through the use of the equation for CNNs
nn.ReLU(),
nn.Linear(512, self.num_actions)
)
# initialize weights utilizing he initialization
# (pytorch already does this for conv layers however not linear layers)
# this isn't essential and nothing you could fear about
self.apply(self._init)
def ahead(self, x):
""" Ahead go. """
# the /255.0 performs normalization of pixel values to be in [0.0, 1.0]
return self.layers(x / 255.0)
def epsilon_greedy(self, state, dim=1):
"""Epsilon grasping. Randomly choose worth with prob e,
else select grasping motion"""
rng = np.random.random() # get random worth between [0, 1]
if rng < self.epsilon: # for prob below e
# random pattern and return as torch tensor
motion = self.env.action_space.pattern()
motion = torch.tensor(motion)
else:
# use torch no grad to verify no gradients are accrued for this
# ahead go
with torch.no_grad():
q_values = self(state)
# select finest motion
motion = torch.argmax(q_values, dim=dim)
return motion
def epsilon_decay(self, step):
# linearly lower epsilon
self.epsilon = self.max_decay + (self.start_epsilon - self.max_decay) * max(0, (self.decay_steps - step) / self.decay_steps)
def _init(self, m):
# initialize layers utilizing he init
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu')
if m.bias just isn't None:
nn.init.zeros_(m.bias)That covers the mannequin structure. I used a linear ε-decay scheme, however be at liberty to attempt one other. We are able to additionally create an auxiliary class that retains monitor of essential metrics. The category retains monitor of rewards obtained for the previous few episodes together with the respective lengths of mentioned episodes.
class MetricTracker:
def __init__(self, window_size=100):
# the dimensions of the historical past we use to trace stats
self.window_size = window_size
self.rewards = deque(maxlen=window_size)
self.current_episode_reward = 0
def add_step_reward(self, reward):
# add obtained reward to the present reward
self.current_episode_reward += reward
def end_episode(self):
# add reward for episode to historical past
self.rewards.append(self.current_episode_reward)
# reset metrics
self.current_episode_reward = 0
# property simply makes it in order that we are able to return this worth with out
# having to name it as a operate
@property
def avg_reward(self):
return np.imply(self.rewards) if self.rewards else 0Nice! Now we now have all the pieces we have to begin coaching our agent. Let’s outline the coaching operate and go over the way it works. Earlier than that, we have to create the required objects to go into our coaching operate together with some hyperparameters. A small word: within the paper the authors use RMSProp, however as a substitute we’ll use Adam. Adam proved to work for me with the given parameters, however you might be welcome to attempt RMSProp or different variations.
TIMESTEPS = 6000000 # whole variety of timesteps for coaching
LR = 2.5e-4 # studying price
BATCH_SIZE = 64 # batch dimension, change based mostly in your {hardware}
C = 10000 # the interval at which we replace the goal community
GAMMA = 0.99 # the low cost worth
TRAIN_FREQ = 4 # within the paper the SGD updates are made each 4 actions
DECAY_START = 0 # when to start out e-decay
FINAL_ANNEAL = 1000000 # when to cease e-decay
# load the buffer
buffer_pong, env_pong = load_buffer(50000, 150000, recreation="PongNoFrameskip-v4")
# create the networks, push the weights of the q_network onto the goal community
q_network_pong = DQN(env_pong, decay_steps=FINAL_ANNEAL).to(system)
target_network_pong = DQN(env_pong, decay_steps=FINAL_ANNEAL).to(system)
target_network_pong.load_state_dict(q_network_pong.state_dict())
# create the optimizer
optimizer_pong = torch.optim.Adam(q_network_pong.parameters(), lr=LR)
# metrics class instantiation
metrics = MetricTracker()def practice(
env,
title, # title of the agent, used to avoid wasting the agent
q_network,
target_network,
optimizer,
timesteps,
replay, # handed buffer
metrics, # metrics class
train_freq, # this parameter works complementary to border skipping
batch_size,
gamma, # low cost parameter
decay_start,
C,
save_step=850000, # I like to recommend setting this one excessive or else a whole lot of fashions shall be saved
):
loss_func = nn.MSELoss() # create the loss object
start_time = time.time() # to examine pace of the coaching process
episode_count = 0
best_avg_reward = -float('inf')
# reset the env
obs, _ = env.reset()
for step in vary(1, timesteps+1): # begin from 1 only for printing progress
# we have to go tensors of dimension (batch_size, ...) to torch
# however the remark is only one so it does not have that dim
# so we add it artificially (step 2 in process)
batched_obs = np.expand_dims(obs.squeeze(), axis=0)
# carry out e-greedy on the remark and convert the tensor into numpy and ship it to the cpu
motion = q_network.epsilon_greedy(torch.as_tensor(batched_obs, dtype=torch.float32, system=system)).cpu().merchandise()
# take an motion
obs_prime, reward, terminated, truncated, _ = env.step(motion)
# retailer the tuple (step 3 within the process)
replay.retailer((obs.squeeze(), motion, reward, obs_prime.squeeze(), terminated or truncated))
metrics.add_step_reward(reward)
obs = obs_prime
# practice each 4 steps as per the paper
if step % train_freq == 0:
# pattern tuples from the replay (step 4 within the process)
observations, actions, rewards, observation_primes, dones = replay.pattern(batch_size)
# we do not need to accumulate gradients for this operation so use no_grad
with torch.no_grad():
q_values_minus = target_network(observation_primes)
# get the max over the goal community
boostrapped_values = torch.amax(q_values_minus, dim=1, keepdim=True)
# this line principally makes in order that for each pattern within the minibatch which signifies
# that the episode is finished, we return the reward, else we return the
# the bootstrapped reward (step 5 within the process)
y_trues = torch.the place(dones, rewards, rewards + gamma * boostrapped_values)
y_preds = q_network(observations)
# compute the loss
# the collect will get the values of the q_network equivalent to the
# motion taken
loss = loss_func(y_preds.collect(1, actions), y_trues)
# set the grads to 0, and carry out the backward go (step 6 within the process)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# begin the e-decay
if step > decay_start:
q_network.epsilon_decay(step)
target_network.epsilon_decay(step)
# if the episode is completed then we print some metrics
if terminated or truncated:
# compute steps per sec
elapsed_time = time.time() - start_time
steps_per_sec = step / elapsed_time
metrics.end_episode()
episode_count += 1
# reset the atmosphere
obs, _ = env.reset()
# save a mannequin if above save_step and if the typical reward has improved
# that is sort of like early-stopping, however we do not cease we simply save a mannequin
if metrics.avg_reward > best_avg_reward and step > save_step:
best_avg_reward = metrics.avg_reward
torch.save({
'step': step,
'model_state_dict': q_network.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'avg_reward': metrics.avg_reward,
}, f"fashions/{title}_dqn_best_{step}.pth")
# print some metrics
print(f"rStep: {step:,}/{timesteps:,} | "
f"Episodes: {episode_count} | "
f"Avg Reward: {metrics.avg_reward:.1f} | "
f"Epsilon: {q_network.epsilon:.3f} | "
f"Steps/sec: {steps_per_sec:.1f}", finish="r")
# replace the goal community
if step % C == 0:
target_network.load_state_dict(q_network.state_dict())The coaching process intently follows Determine 6 and the algorithm described within the paper [4]. We first create the required objects such because the loss operate and so on and reset the atmosphere. Then we are able to begin the coaching loop, through the use of the Q-network to provide us an motion based mostly on the ε-greedy coverage. We simulate the atmosphere one step ahead utilizing the motion and push the resultant tuple onto the replay. If the replace frequency situation is met, we are able to proceed with a coaching step. The motivation behind the replace frequency aspect is one thing I’m not 100% assured in. At the moment, the reason I can present revolves round computational effectivity: coaching each 4 steps as a substitute of each step majorly hastens the algorithm and appears to work comparatively nicely. Within the replace step itself, we pattern a minibatch of tuples and run the mannequin ahead to provide predicted Q-values. We then create the goal values (the bootstrapped true labels) utilizing the piecewise operate in step 5 in Determine 6. Performing an SGD step turns into fairly easy from this level, since we are able to depend on autograd to compute the gradients and the optimizer to replace the parameters.
If you happen to adopted alongside till now, you need to use the next take a look at operate to check your saved mannequin.
def take a look at(recreation, mannequin, num_eps=2):
# render human opens an occasion of the sport so you may see it
env_test = make_env(recreation, render="human")
# load the mannequin
q_network_trained = DQN(env_test)
q_network_trained.load_state_dict(torch.load(mannequin, weights_only=False)['model_state_dict'])
q_network_trained.eval() # set the mannequin to inference mode (no gradients and so on)
q_network_trained.epsilon = 0.05 # a small quantity of stochasticity
rewards_list = []
# run for set quantity of episodes
for episode in vary(num_eps):
print(f'Episode {episode}', finish='r', flush=True)
# reset the env
obs, _ = env_test.reset()
achieved = False
total_reward = 0
# till the episode just isn't achieved, carry out the motion from the q-network
whereas not achieved:
batched_obs = np.expand_dims(obs.squeeze(), axis=0)
motion = q_network_trained.epsilon_greedy(torch.as_tensor(batched_obs, dtype=torch.float32)).cpu().merchandise()
next_observation, reward, terminated, truncated, _ = env_test.step(motion)
total_reward += reward
obs = next_observation
achieved = terminated or truncated
rewards_list.append(total_reward)
# shut the atmosphere, since we use render human
env_test.shut()
print(f'Common episode reward achieved: {np.imply(rewards_list)}')Right here’s how you need to use it:
# be sure you use your newest mannequin! I additionally renamed my mannequin path so
# take that under consideration
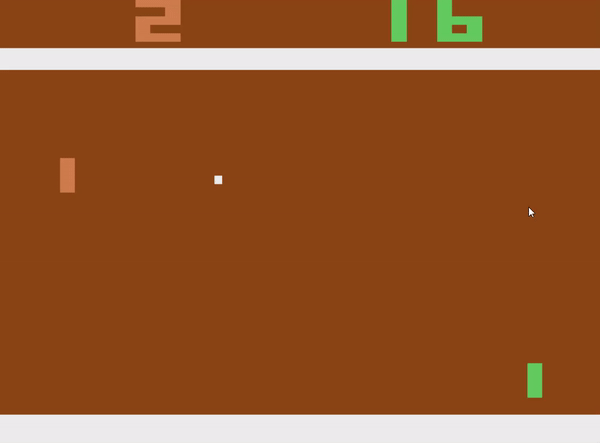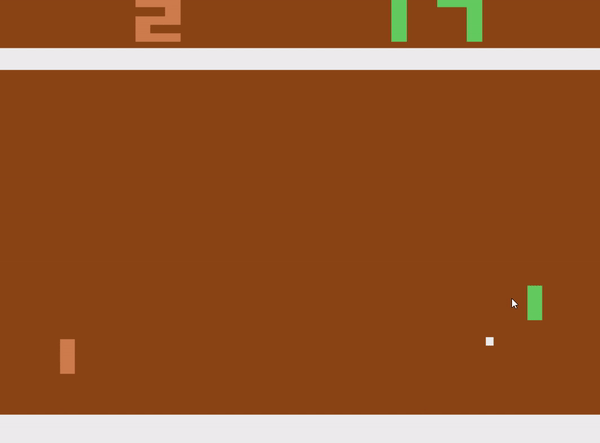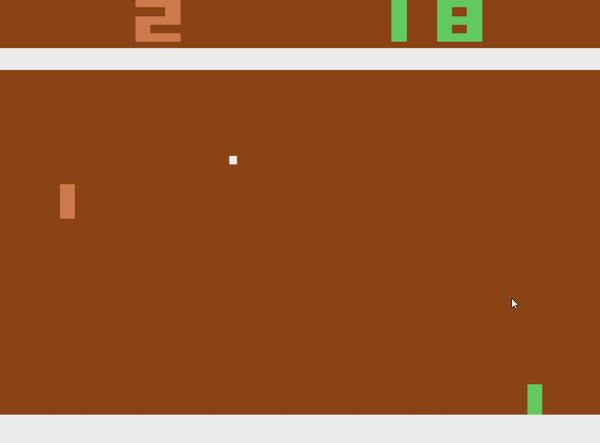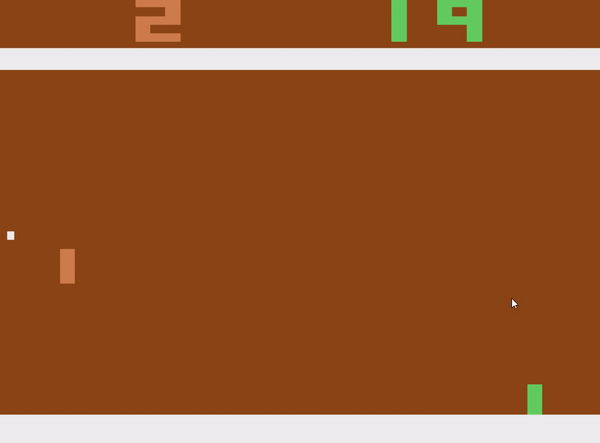
take a look at('PongNoFrameskip-v4', 'fashions/pong_dqn_best_6M.pth')That’s all the pieces for the code! You possibly can see a skilled agent beneath in Determine 8. It behaves fairly much like a human would possibly play Pong, and is ready to (persistently) beat the AI on the best issue. This naturally invitations the query, how nicely does it carry out on greater difficulties? Attempt it out utilizing your individual agent or my skilled one!
A further agent was skilled on the sport Breakout as nicely, the agent could be seen in Determine 9. As soon as once more, I used the default mode and issue. It is likely to be fascinating to see how nicely it performs in numerous modes or difficulties.
Abstract
DQN solves the problem of coaching brokers to play Atari video games. By utilizing a FA, expertise replay and so on, we’re in a position to practice an agent that mimics and even surpasses human efficiency in Atari video games [3]. Deep-RL brokers could be finicky and also you might need observed that we use a lot of strategies to make sure that coaching is steady. If issues are going unsuitable along with your implementation it won’t harm to have a look at the small print once more.
If you wish to take a look at the code for my implementation you need to use this link. The repo additionally accommodates code to coach your individual mannequin on the sport of your alternative (so long as it’s in ALE), in addition to the skilled weights for each Pong and Breakout.
I hope this was a useful introduction to coaching DQN brokers. To take issues to the subsequent degree possibly you may attempt to tweak particulars to beat the upper difficulties. If you wish to look additional, there are lots of extensions to DQN you may discover, equivalent to Dueling DQNs, Prioritized Replay and so on.
References
[1] A. L. Samuel, “Some Research in Machine Studying Utilizing the Recreation of Checkers,” IBM Journal of Analysis and Growth, vol. 3, no. 3, pp. 210–229, 1959. doi:10.1147/rd.33.0210.
[2] Sammut, Claude; Webb, Geoffrey I., eds. (2010), “TD-Gammon”, Encyclopedia of Machine Studying, Boston, MA: Springer US, pp. 955–956, doi:10.1007/978–0–387–30164–8_813, ISBN 978–0–387–30164–8, retrieved 2023–12–25
[3] Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, … and Demis Hassabis. “Human-Stage Management by means of Deep Reinforcement Studying.” Nature 518, no. 7540 (2015): 529–533. https://doi.org/10.1038/nature14236
[4] Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, … and Demis Hassabis. “Enjoying Atari with Deep Reinforcement Studying.” arXiv preprint arXiv:1312.5602 (2013). https://arxiv.org/abs/1312.5602
[5] Sutton, Richard S., and Andrew G. Barto. Reinforcement Studying: An Introduction. 2nd ed., MIT Press, 2018.
[6] Russell, Stuart J., and Peter Norvig. Synthetic Intelligence: A Trendy Strategy. 4th ed., Pearson, 2020.
[7] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Studying. MIT Press.
[8] Bailey, Jay. Deep Q-Networks Defined. 13 Sept. 2022, www.lesswrong.com/posts/kyvCNgx9oAwJCuevo/deep-q-networks-explained.
[9] Hausknecht, M., & Stone, P. (2015). Deep recurrent Q-learning for partially observable MDPs. arXiv preprint arXiv:1507.06527. https://arxiv.org/abs/1507.06527
Source link