
Introduction
AI is in every single place.
It’s laborious to not work together not less than as soon as a day with a Giant Language Mannequin (LLM). The chatbots are right here to remain. They’re in your apps, they enable you to write higher, they compose emails, they learn emails…properly, they do quite a bit.
And I don’t assume that that’s unhealthy. The truth is, my opinion is the opposite means – not less than thus far. I defend and advocate for the usage of AI in our each day lives as a result of, let’s agree, it makes all the things a lot simpler.
I don’t need to spend time double-reading a doc to search out punctuation issues or sort. AI does that for me. I don’t waste time writing that follow-up e mail each single Monday. AI does that for me. I don’t must learn an enormous and boring contract when I’ve an AI to summarize the principle takeaways and motion factors to me!
These are solely a few of AI’s nice makes use of. In case you’d prefer to know extra use circumstances of LLMs to make our lives simpler, I wrote a complete e book about them.
Now, considering as an information scientist and looking out on the technical aspect, not all the things is that vivid and glossy.
LLMs are nice for a number of normal use circumstances that apply to anybody or any firm. For instance, coding, summarizing, or answering questions on normal content material created till the coaching cutoff date. Nevertheless, in terms of particular enterprise functions, for a single function, or one thing new that didn’t make the cutoff date, that’s when the fashions received’t be that helpful if used out-of-the-box – which means, they won’t know the reply. Thus, it can want changes.
Coaching an LLM mannequin can take months and thousands and thousands of {dollars}. What’s even worse is that if we don’t modify and tune the mannequin to our function, there might be unsatisfactory outcomes or hallucinations (when the mannequin’s response doesn’t make sense given our question).
So what’s the answer, then? Spending some huge cash retraining the mannequin to incorporate our knowledge?
Not likely. That’s when the Retrieval-Augmented Technology (RAG) turns into helpful.
RAG is a framework that mixes getting data from an exterior information base with giant language fashions (LLMs). It helps AI fashions produce extra correct and related responses.
Let’s be taught extra about RAG subsequent.
What’s RAG?
Let me let you know a narrative for instance the idea.
I like films. For a while up to now, I knew which films have been competing for the most effective film class on the Oscars or the most effective actors and actresses. And I will surely know which of them received the statue for that 12 months. However now I’m all rusty on that topic. In case you requested me who was competing, I’d not know. And even when I attempted to reply you, I’d offer you a weak response.
So, to offer you a top quality response, I’ll do what everyone else does: seek for the knowledge on-line, receive it, after which give it to you. What I simply did is identical thought because the RAG: I obtained knowledge from an exterior database to present you a solution.
After we improve the LLM with a content material retailer the place it may possibly go and retrieve knowledge to increase (improve) its information base, that’s the RAG framework in motion.
RAG is like making a content material retailer the place the mannequin can improve its information and reply extra precisely.
Summarizing:
- Makes use of search algorithms to question exterior knowledge sources, akin to databases, information bases, and net pages.
- Pre-processes the retrieved data.
- Incorporates the pre-processed data into the LLM.
Why use RAG?
Now that we all know what the RAG framework is let’s perceive why we needs to be utilizing it.
Listed here are among the advantages:
- Enhances factual accuracy by referencing actual knowledge.
- RAG will help LLMs course of and consolidate information to create extra related solutions
- RAG will help LLMs entry further information bases, akin to inner organizational knowledge
- RAG will help LLMs create extra correct domain-specific content material
- RAG will help cut back information gaps and AI hallucination
As beforehand defined, I prefer to say that with the RAG framework, we’re giving an inner search engine for the content material we wish it so as to add to the information base.
Properly. All of that may be very fascinating. However let’s see an software of RAG. We’ll discover ways to create an AI-powered PDF Reader Assistant.
Mission
That is an software that enables customers to add a PDF doc and ask questions on its content material utilizing AI-powered pure language processing (NLP) instruments.
- The app makes use of
Streamlitbecause the entrance finish. Langchain, OpenAI’s GPT-4 mannequin, andFAISS(Fb AI Similarity Search) for doc retrieval and query answering within the backend.
Let’s break down the steps for higher understanding:
- Loading a PDF file and splitting it into chunks of textual content.
- This makes the information optimized for retrieval
- Current the chunks to an embedding device.
- Embeddings are numerical vector representations of information used to seize relationships, similarities, and meanings in a means that machines can perceive. They’re extensively utilized in Pure Language Processing (NLP), recommender techniques, and serps.
- Subsequent, we put these chunks of textual content and embeddings in the identical DB for retrieval.
- Lastly, we make it out there to the LLM.
Information preparation
Making ready a content material retailer for the LLM will take some steps, as we simply noticed. So, let’s begin by making a perform that may load a file and break up it into textual content chunks for environment friendly retrieval.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and break up it into chunks for environment friendly retrieval.
:param pdf: PDF file to load
:return: Listing of chunks of textual content
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Textual content Splitter with Chunk Dimension of 500 phrases and Overlap of 100 phrases in order that context just isn't misplaced
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Break up into chunks for environment friendly retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunksSubsequent, we are going to begin constructing our Streamlit app, and we’ll use that perform within the subsequent script.
Net software
We’ll start importing the required modules in Python. Most of these will come from the langchain packages.
FAISS is used for doc retrieval; OpenAIEmbeddings transforms the textual content chunks into numerical scores for higher similarity calculation by the LLM; ChatOpenAI is what permits us to work together with the OpenAI API; create_retrieval_chain is what truly the RAG does, retrieving and augmenting the LLM with that knowledge; create_stuff_documents_chain glues the mannequin and the ChatPromptTemplate.
Notice: You will have to generate an OpenAI Key to have the ability to run this script. If it’s the primary time you’re creating your account, you get some free credit. However when you have it for a while, it’s doable that you’ll have to add 5 {dollars} in credit to have the ability to entry OpenAI’s API. An possibility is utilizing Hugging Face’s Embedding.
# Imports
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.chains import create_retrieval_chain
from langchain_openai import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from scripts.secret import OPENAI_KEY
from scripts.document_loader import load_document
import streamlit as stThis primary code snippet will create the App title, create a field for file add, and put together the file to be added to the load_document() perform.
# Create a Streamlit app
st.title("AI-Powered Doc Q&A")
# Load doc to streamlit
uploaded_file = st.file_uploader("Add a PDF file", sort="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work round doc loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.identify
# Load doc and break up it into chunks for environment friendly retrieval.
chunks = load_document(temp_file)
# Message person that doc is being processed with time emoji
st.write("Processing doc... :watch:")Machines perceive numbers higher than textual content, so ultimately, we must present the mannequin with a database of numbers that it may possibly evaluate and verify for similarity when performing a question. That’s the place the embeddings might be helpful to create the vector_db, on this subsequent piece of code.
# Generate embeddings
# Embeddings are numerical vector representations of information, usually used to seize relationships, similarities,
# and meanings in a means that machines can perceive. They're extensively utilized in Pure Language Processing (NLP),
# recommender techniques, and serps.
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY,
mannequin="text-embedding-ada-002")
# Also can use HuggingFaceEmbeddings
# from langchain_huggingface.embeddings import HuggingFaceEmbeddings
# embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# Create vector database containing chunks and embeddings
vector_db = FAISS.from_documents(chunks, embeddings)Subsequent, we create a retriever object to navigate within the vector_db.
# Create a doc retriever
retriever = vector_db.as_retriever()
llm = ChatOpenAI(model_name="gpt-4o-mini", openai_api_key=OPENAI_KEY)Then, we are going to create the system_prompt, which is a set of directions to the LLM on tips on how to reply, and we are going to create a immediate template, making ready it to be added to the mannequin as soon as we get the enter from the person.
# Create a system immediate
# It units the general context for the mannequin.
# It influences tone, type, and focus earlier than person interplay begins.
# Not like person inputs, a system immediate just isn't seen to the top person.
system_prompt = (
"You're a useful assistant. Use the given context to reply the query."
"If you do not know the reply, say you do not know. "
"{context}"
)
# Create a immediate Template
immediate = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
# Create a sequence
# It creates a StuffDocumentsChain, which takes a number of paperwork (textual content knowledge) and "stuffs" them collectively earlier than passing them to the LLM for processing.
question_answer_chain = create_stuff_documents_chain(llm, immediate)Transferring on, we create the core of the RAG framework, pasting collectively the retriever object and the immediate. This object provides related paperwork from an information supply (e.g., a vector database) and makes it able to be processed utilizing an LLM to generate a response.
# Creates the RAG
chain = create_retrieval_chain(retriever, question_answer_chain)Lastly, we create the variable query for the person enter. If this query field is stuffed with a question, we move it to the chain, which calls the LLM to course of and return the response, which might be printed on the app’s display screen.
# Streamlit enter for query
query = st.text_input("Ask a query concerning the doc:")
if query:
# Reply
response = chain.invoke({"enter": query})['answer']
st.write(response)Here’s a screenshot of the end result.
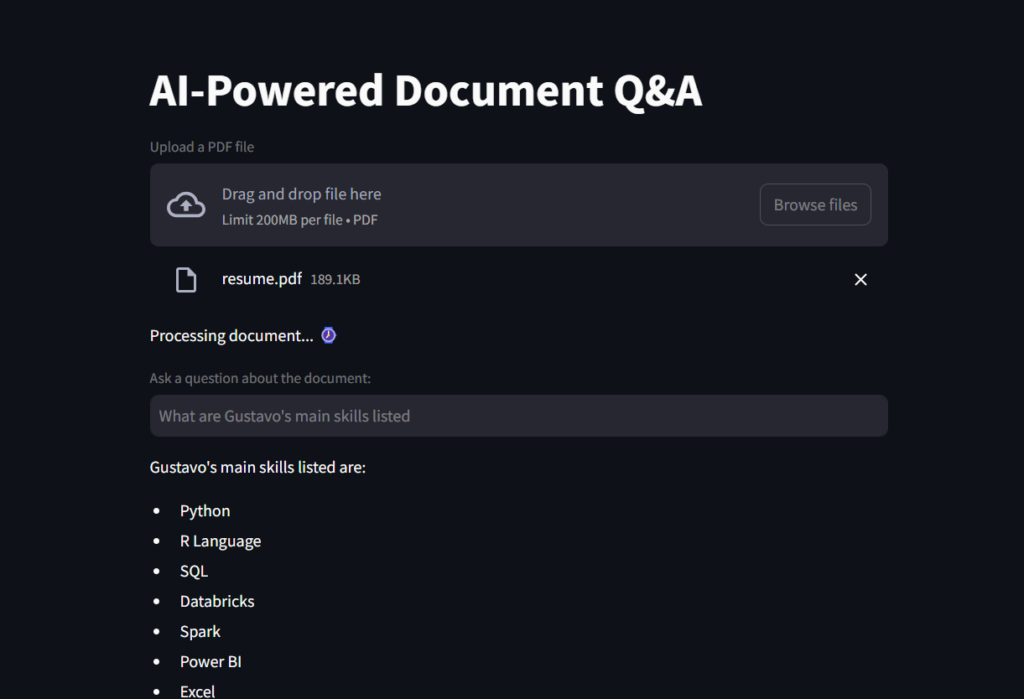
And this can be a GIF so that you can see the File Reader Ai Assistant in motion!
Earlier than you go
On this undertaking, we realized what the RAG framework is and the way it helps the Llm to carry out higher and likewise carry out properly with particular information.
AI might be powered with information from an instruction handbook, databases from an organization, some finance recordsdata, or contracts, after which grow to be fine-tuned to reply precisely to domain-specific content material queries. The information base is augmented with a content material retailer.
To recap, that is how the framework works:
1️⃣ Consumer Question → Enter textual content is acquired.
2️⃣ Retrieve Related Paperwork → Searches a information base (e.g., a database, vector retailer).
3️⃣ Increase Context → Retrieved paperwork are added to the enter.
4️⃣ Generate Response → An LLM processes the mixed enter and produces a solution.
GitHub repository
https://github.com/gurezende/Basic-Rag
About me
In case you favored this content material and wish to be taught extra about my work, right here is my web site, the place you may as well discover all my contacts.
References
https://cloud.google.com/use-cases/retrieval-augmented-generation
https://www.ibm.com/think/topics/retrieval-augmented-generation
https://python.langchain.com/docs/introduction
https://www.geeksforgeeks.org/how-to-get-your-own-openai-api-key