
Introduction
Many generative AI use circumstances nonetheless revolve round Retrieval Augmented Era (RAG), but constantly fall in need of person expectations. Regardless of the rising physique of analysis on RAG enhancements and even including Brokers into the method, many options nonetheless fail to return exhaustive outcomes, miss info that’s crucial however sometimes talked about within the paperwork, require a number of search iterations, and usually battle to reconcile key themes throughout a number of paperwork. To high all of it off, many implementations nonetheless depend on cramming as a lot “related” info as attainable into the mannequin’s context window alongside detailed system and person prompts. Reconciling all this info typically exceeds the mannequin’s cognitive capability and compromises response high quality and consistency.
That is the place our Agentic Data Distillation + Pyramid Search Method comes into play. As a substitute of chasing the perfect chunking technique, retrieval algorithm, or inference-time reasoning technique, my staff, Jim Brown, Mason Sawtell, Sandi Besen, and I, take an agentic method to doc ingestion.
We leverage the total functionality of the mannequin at ingestion time to focus completely on distilling and preserving probably the most significant info from the doc dataset. This basically simplifies the RAG course of by permitting the mannequin to direct its reasoning talents towards addressing the person/system directions moderately than struggling to know formatting and disparate info throughout doc chunks.
We particularly goal high-value questions which are typically troublesome to judge as a result of they’ve a number of right solutions or answer paths. These circumstances are the place conventional RAG options battle most and present RAG analysis datasets are largely inadequate for testing this downside house. For our analysis implementation, we downloaded annual and quarterly stories from the final yr for the 30 corporations within the DOW Jones Industrial Common. These paperwork may be discovered by the SEC EDGAR website. The information on EDGAR is accessible and able to be downloaded for free or may be queried by EDGAR public searches. See the SEC privacy policy for extra particulars, info on the SEC web site is “thought-about public info and could also be copied or additional distributed by customers of the web page with out the SEC’s permission”. We chosen this dataset for 2 key causes: first, it falls exterior the information cutoff for the fashions evaluated, guaranteeing that the fashions can not reply to questions based mostly on their information from pre-training; second, it’s an in depth approximation for real-world enterprise issues whereas permitting us to debate and share our findings utilizing publicly accessible knowledge.
Whereas typical RAG options excel at factual retrieval the place the reply is well recognized within the doc dataset (e.g., “When did Apple’s annual shareholder’s assembly happen?”), they battle with nuanced questions that require a deeper understanding of ideas throughout paperwork (e.g., “Which of the DOW corporations has probably the most promising AI technique?”). Our Agentic Data Distillation + Pyramid Search Method addresses these kind of questions with a lot larger success in comparison with different normal approaches we examined and overcomes limitations related to utilizing information graphs in RAG programs.
On this article, we’ll cowl how our information distillation course of works, key advantages of this method, examples, and an open dialogue on one of the simplest ways to judge these kind of programs the place, in lots of circumstances, there is no such thing as a singular “proper” reply.
Constructing the pyramid: How Agentic Data Distillation works
Overview
Our information distillation course of creates a multi-tiered pyramid of knowledge from the uncooked supply paperwork. Our method is impressed by the pyramids utilized in deep studying laptop vision-based duties, which permit a mannequin to research a picture at a number of scales. We take the contents of the uncooked doc, convert it to markdown, and distill the content material into a listing of atomic insights, associated ideas, doc abstracts, and common recollections/reminiscences. Throughout retrieval it’s attainable to entry all or any ranges of the pyramid to reply to the person request.
distill paperwork and construct the pyramid:
- Convert paperwork to Markdown: Convert all uncooked supply paperwork to Markdown. We’ve discovered fashions course of markdown greatest for this process in comparison with different codecs like JSON and it’s extra token environment friendly. We used Azure Doc Intelligence to generate the markdown for every web page of the doc, however there are a lot of different open-source libraries like MarkItDown which do the identical factor. Our dataset included 331 paperwork and 16,601 pages.
- Extract atomic insights from every web page: We course of paperwork utilizing a two-page sliding window, which permits every web page to be analyzed twice. This offers the agent the chance to right any potential errors when processing the web page initially. We instruct the mannequin to create a numbered record of insights that grows because it processes the pages within the doc. The agent can overwrite insights from the earlier web page in the event that they have been incorrect because it sees every web page twice. We instruct the mannequin to extract insights in easy sentences following the subject-verb-object (SVO) format and to jot down sentences as if English is the second language of the person. This considerably improves efficiency by encouraging readability and precision. Rolling over every web page a number of occasions and utilizing the SVO format additionally solves the disambiguation downside, which is a large problem for information graphs. The perception era step can be significantly useful for extracting info from tables for the reason that mannequin captures the info from the desk in clear, succinct sentences. Our dataset produced 216,931 complete insights, about 13 insights per web page and 655 insights per doc.
- Distilling ideas from insights: From the detailed record of insights, we establish higher-level ideas that join associated details about the doc. This step considerably reduces noise and redundant info within the doc whereas preserving important info and themes. Our dataset produced 14,824 complete ideas, about 1 idea per web page and 45 ideas per doc.
- Creating abstracts from ideas: Given the insights and ideas within the doc, the LLM writes an summary that seems each higher than any summary a human would write and extra information-dense than any summary current within the unique doc. The LLM generated summary supplies extremely complete information in regards to the doc with a small token density that carries a major quantity of knowledge. We produce one summary per doc, 331 complete.
- Storing recollections/reminiscences throughout paperwork: On the high of the pyramid we retailer crucial info that’s helpful throughout all duties. This may be info that the person shares in regards to the process or info the agent learns in regards to the dataset over time by researching and responding to duties. For instance, we will retailer the present 30 corporations within the DOW as a recollection since this record is totally different from the 30 corporations within the DOW on the time of the mannequin’s information cutoff. As we conduct increasingly analysis duties, we will repeatedly enhance our recollections and preserve an audit path of which paperwork these recollections originated from. For instance, we will preserve monitor of AI methods throughout corporations, the place corporations are making main investments, and so forth. These high-level connections are tremendous essential since they reveal relationships and data that aren’t obvious in a single web page or doc.
We retailer the textual content and embeddings for every layer of the pyramid (pages and up) in Azure PostgreSQL. We initially used Azure AI Search, however switched to PostgreSQL for price causes. This required us to jot down our personal hybrid search operate since PostgreSQL doesn’t but natively help this function. This implementation would work with any vector database or vector index of your selecting. The important thing requirement is to retailer and effectively retrieve each textual content and vector embeddings at any degree of the pyramid.
This method basically creates the essence of a information graph, however shops info in pure language, the best way an LLM natively needs to work together with it, and is extra environment friendly on token retrieval. We additionally let the LLM decide the phrases used to categorize every degree of the pyramid, this appeared to let the mannequin determine for itself one of the simplest ways to explain and differentiate between the data saved at every degree. For instance, the LLM most well-liked “insights” to “info” because the label for the primary degree of distilled information. Our aim in doing this was to higher perceive how an LLM thinks in regards to the course of by letting it determine easy methods to retailer and group associated info.
Utilizing the pyramid: The way it works with RAG & Brokers
At inference time, each conventional RAG and agentic approaches profit from the pre-processed, distilled info ingested in our information pyramid. The pyramid construction permits for environment friendly retrieval in each the standard RAG case, the place solely the highest X associated items of knowledge are retrieved or within the Agentic case, the place the Agent iteratively plans, retrieves, and evaluates info earlier than returning a remaining response.
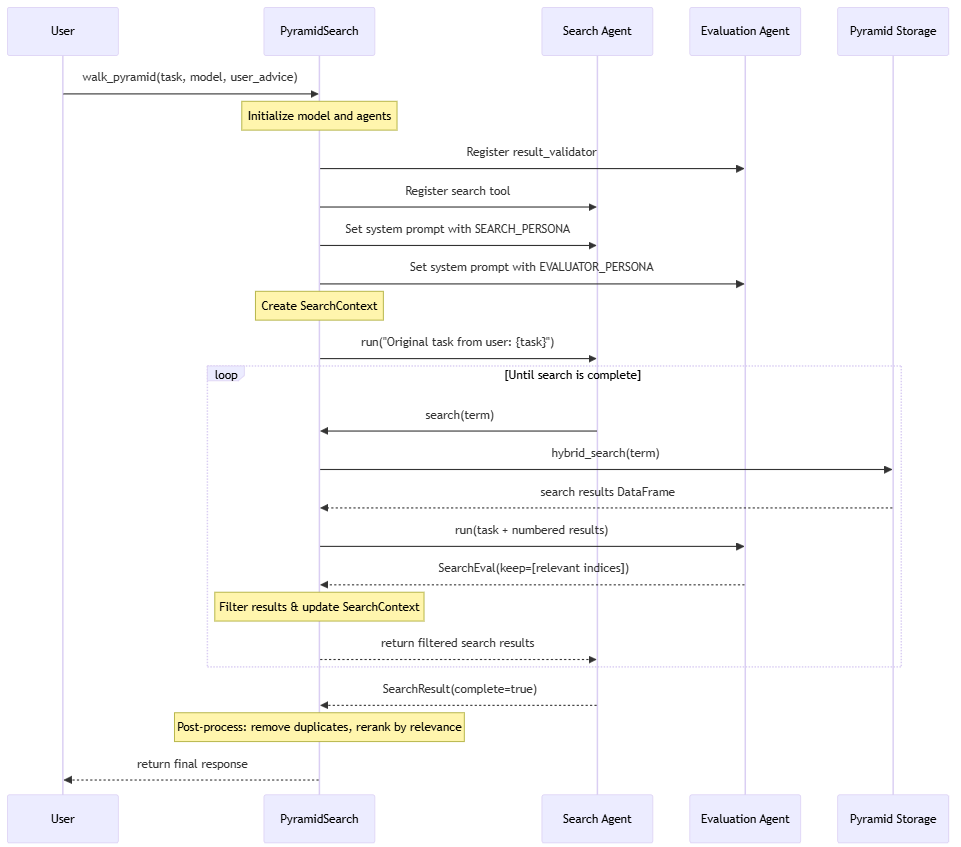
The advantage of the pyramid method is that info at any and all ranges of the pyramid can be utilized throughout inference. For our implementation, we used PydanticAI to create a search agent that takes within the person request, generates search phrases, explores concepts associated to the request, and retains monitor of knowledge related to the request. As soon as the search agent determines there’s ample info to deal with the person request, the outcomes are re-ranked and despatched again to the LLM to generate a remaining reply. Our implementation permits a search agent to traverse the data within the pyramid because it gathers particulars a few idea/search time period. That is just like strolling a information graph, however in a method that’s extra pure for the LLM since all the data within the pyramid is saved in pure language.
Relying on the use case, the Agent might entry info in any respect ranges of the pyramid or solely at particular ranges (e.g. solely retrieve info from the ideas). For our experiments, we didn’t retrieve uncooked page-level knowledge since we wished to give attention to token effectivity and located the LLM-generated info for the insights, ideas, abstracts, and recollections was ample for finishing our duties. In concept, the Agent might even have entry to the web page knowledge; this would supply extra alternatives for the agent to re-examine the unique doc textual content; nevertheless, it could additionally considerably enhance the overall tokens used.
Here’s a high-level visualization of our Agentic method to responding to person requests:
Outcomes from the pyramid: Actual-world examples
To judge the effectiveness of our method, we examined it in opposition to quite a lot of query classes, together with typical fact-finding questions and sophisticated cross-document analysis and evaluation duties.
Reality-finding (spear fishing):
These duties require figuring out particular info or info which are buried in a doc. These are the sorts of questions typical RAG options goal however typically require many searches and devour plenty of tokens to reply accurately.
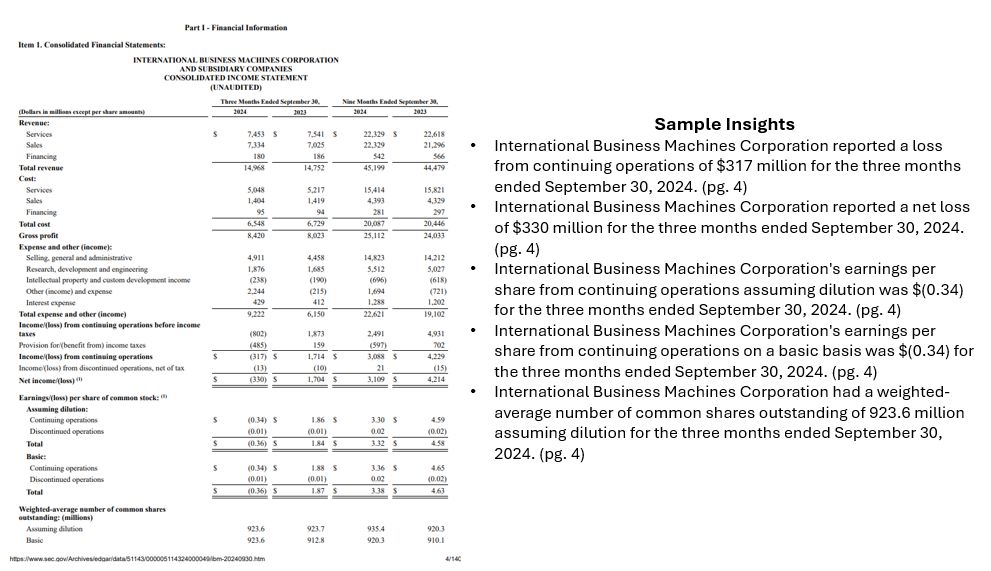
Instance process: “What was IBM’s complete income within the newest monetary reporting?”
Instance response utilizing pyramid method: “IBM’s complete income for the third quarter of 2024 was $14.968 billion [ibm-10q-q3-2024.pdf, pg. 4]

This result’s right (human-validated) and was generated utilizing solely 9,994 complete tokens, with 1,240 tokens within the generated remaining response.
Complicated analysis and evaluation:
These duties contain researching and understanding a number of ideas to realize a broader understanding of the paperwork and make inferences and knowledgeable assumptions based mostly on the gathered info.
Instance process: “Analyze the investments Microsoft and NVIDIA are making in AI and the way they’re positioning themselves available in the market. The report must be clearly formatted.”
Instance response:
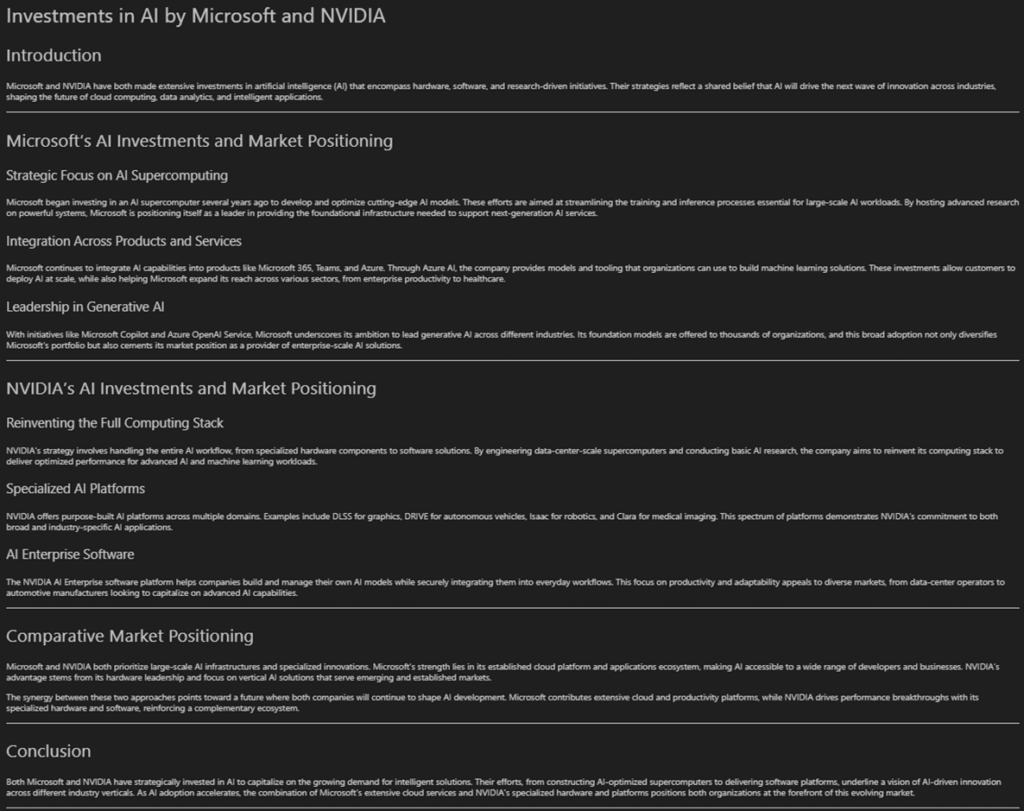
The result’s a complete report that executed rapidly and accommodates detailed details about every of the businesses. 26,802 complete tokens have been used to analysis and reply to the request with a major proportion of them used for the ultimate response (2,893 tokens or ~11%). These outcomes have been additionally reviewed by a human to confirm their validity.

Instance process: “Create a report on analyzing the dangers disclosed by the varied monetary corporations within the DOW. Point out which dangers are shared and distinctive.”
Instance response:


Equally, this process was accomplished in 42.7 seconds and used 31,685 complete tokens, with 3,116 tokens used to generate the ultimate report.

These outcomes for each fact-finding and sophisticated evaluation duties display that the pyramid method effectively creates detailed stories with low latency utilizing a minimal quantity of tokens. The tokens used for the duties carry dense which means with little noise permitting for high-quality, thorough responses throughout duties.
Advantages of the pyramid: Why use it?
General, we discovered that our pyramid method supplied a major increase in response high quality and total efficiency for high-value questions.
Among the key advantages we noticed embrace:
- Decreased mannequin’s cognitive load: When the agent receives the person process, it retrieves pre-processed, distilled info moderately than the uncooked, inconsistently formatted, disparate doc chunks. This basically improves the retrieval course of for the reason that mannequin doesn’t waste its cognitive capability on attempting to interrupt down the web page/chunk textual content for the primary time.
- Superior desk processing: By breaking down desk info and storing it in concise however descriptive sentences, the pyramid method makes it simpler to retrieve related info at inference time by pure language queries. This was significantly essential for our dataset since monetary stories comprise plenty of crucial info in tables.
- Improved response high quality to many sorts of requests: The pyramid permits extra complete context-aware responses to each exact, fact-finding questions and broad evaluation based mostly duties that contain many themes throughout quite a few paperwork.
- Preservation of crucial context: Because the distillation course of identifies and retains monitor of key info, essential info which may seem solely as soon as within the doc is less complicated to keep up. For instance, noting that each one tables are represented in thousands and thousands of {dollars} or in a specific forex. Conventional chunking strategies typically trigger the sort of info to slide by the cracks.
- Optimized token utilization, reminiscence, and velocity: By distilling info at ingestion time, we considerably scale back the variety of tokens required throughout inference, are in a position to maximize the worth of knowledge put within the context window, and enhance reminiscence use.
- Scalability: Many options battle to carry out as the scale of the doc dataset grows. This method supplies a way more environment friendly solution to handle a big quantity of textual content by solely preserving crucial info. This additionally permits for a extra environment friendly use of the LLMs context window by solely sending it helpful, clear info.
- Environment friendly idea exploration: The pyramid permits the agent to discover associated info just like navigating a information graph, however doesn’t require ever producing or sustaining relationships within the graph. The agent can use pure language completely and preserve monitor of essential info associated to the ideas it’s exploring in a extremely token-efficient and fluid method.
- Emergent dataset understanding: An sudden good thing about this method emerged throughout our testing. When asking questions like “what are you able to inform me about this dataset?” or “what sorts of questions can I ask?”, the system is ready to reply and recommend productive search matters as a result of it has a extra sturdy understanding of the dataset context by accessing larger ranges within the pyramid just like the abstracts and recollections.
Past the pyramid: Analysis challenges & future instructions
Challenges
Whereas the outcomes we’ve noticed when utilizing the pyramid search method have been nothing in need of wonderful, discovering methods to ascertain significant metrics to judge all the system each at ingestion time and through info retrieval is difficult. Conventional RAG and Agent analysis frameworks typically fail to deal with nuanced questions and analytical responses the place many alternative responses are legitimate.
Our staff plans to jot down a analysis paper on this method sooner or later, and we’re open to any ideas and suggestions from the group, particularly on the subject of analysis metrics. Lots of the present datasets we discovered have been targeted on evaluating RAG use circumstances inside one doc or exact info retrieval throughout a number of paperwork moderately than sturdy idea and theme evaluation throughout paperwork and domains.
The principle use circumstances we’re inquisitive about relate to broader questions which are consultant of how companies truly need to work together with GenAI programs. For instance, “inform me every little thing I must find out about buyer X” or “how do the behaviors of Buyer A and B differ? Which am I extra more likely to have a profitable assembly with?”. All these questions require a deep understanding of knowledge throughout many sources. The solutions to those questions usually require an individual to synthesize knowledge from a number of areas of the enterprise and suppose critically about it. In consequence, the solutions to those questions are hardly ever written or saved anyplace which makes it inconceivable to easily retailer and retrieve them by a vector index in a typical RAG course of.
One other consideration is that many real-world use circumstances contain dynamic datasets the place paperwork are constantly being added, edited, and deleted. This makes it troublesome to judge and monitor what a “right” response is for the reason that reply will evolve because the accessible info modifications.
Future instructions
Sooner or later, we consider that the pyramid method can handle a few of these challenges by enabling more practical processing of dense paperwork and storing discovered info as recollections. Nonetheless, monitoring and evaluating the validity of the recollections over time will probably be crucial to the system’s total success and stays a key focus space for our ongoing work.
When making use of this method to organizational knowledge, the pyramid course of is also used to establish and assess discrepancies throughout areas of the enterprise. For instance, importing all of an organization’s gross sales pitch decks might floor the place sure services or products are being positioned inconsistently. It is also used to check insights extracted from varied line of enterprise knowledge to assist perceive if and the place groups have developed conflicting understandings of matters or totally different priorities. This software goes past pure info retrieval use circumstances and would enable the pyramid to function an organizational alignment instrument that helps establish divergences in messaging, terminology, and total communication.
Conclusion: Key takeaways and why the pyramid method issues
The information distillation pyramid method is critical as a result of it leverages the total energy of the LLM at each ingestion and retrieval time. Our method permits you to retailer dense info in fewer tokens which has the additional advantage of decreasing noise within the dataset at inference. Our method additionally runs in a short time and is extremely token environment friendly, we’re in a position to generate responses inside seconds, discover probably a whole bunch of searches, and on common use <40K tokens for all the search, retrieval, and response era course of (this contains all of the search iterations!).
We discover that the LLM is way higher at writing atomic insights as sentences and that these insights successfully distill info from each text-based and tabular knowledge. This distilled info written in pure language may be very simple for the LLM to know and navigate at inference because it doesn’t need to expend pointless vitality reasoning about and breaking down doc formatting or filtering by noise.
The power to retrieve and mixture info at any degree of the pyramid additionally supplies vital flexibility to deal with quite a lot of question sorts. This method provides promising efficiency for big datasets and permits high-value use circumstances that require nuanced info retrieval and evaluation.
Observe: The opinions expressed on this article are solely my very own and don’t essentially mirror the views or insurance policies of my employer.
Occupied with discussing additional or collaborating? Attain out on LinkedIn!